2024年6月7-9日,国际应用计量经济学会(IAAE)2024年会在厦门大学经济楼成功举办。这是IAAE年会首次在中国举办,厦门大学是中国首个承办国际应用计量经济学会年会的高校。

本次会议由厦门大学邹至庄经济研究院、厦门大学经济学院、中国科学院数学与系统科学研究院预测科学研究中心、国家自然科学基金委员会“计量建模与经济政策研究”基础科学中心联合承办,北京搜知数据科技有限公司赞助。
汇名家思想、聚学者观点,三天议程中,主办方共安排6场主题演讲,带来最前沿的计量经济学研究成果。
IAAE Lecture
Cheng Hsiao, University of Southern California
Panel Measurement of Treatment Effects (A Nontechnical Review)

7日上午,美国南加州大学萧政教授带来主题报告。他首先简要介绍面板数据、时间序列数据和截面数据,并从多个角度说明面板数据提供了同时捕捉个体间差异和个体内部动态性的可能性。随后,他介绍了个体处理效应(处理和未被处理时对应结果的差值)及其估计。对于单个个体,只有一个结果(处理或未处理)可以观测到,因此估计量的偏差和方差只依赖于另一个不可观测结果的估计。
接着,萧政教授回顾了文献中已有的两大类估计方法,分别是因果方法和非因果(非参数)方法。在因果方法中,萧教授详细介绍了面板回归模型方法和潜在变量(因子模型)方法。与传统回归分析不同,面板回归模型方法不依赖工具变量的存在性。面板数据的因子模型中,将观测值看作时间序列数据和截面数据,然后分别对其建立因子模型,并在N>T和T>N的情形下讨论了模型的参数估计方法。在非因果方法中,萧教授详细介绍了线性投影(linear projection; LP)法。
基于上述估计方法,可以得到处理效应的预测值,一个自然的问题是上述两类方法对于预测的准确性如何?在N和T的不同情形下,萧政教授从理论上给出了渐近均方预测误差意义下的较优方法,并通过数值模拟验证了理论结果。
萧政教授最后总结道,当某一政策有宏观或全局影响时,需要考虑基于方程组而非本报告中介绍的单一方程的方法。此外,当政策变化导致决策规则发生改变时,仅基于特定政策变化变量的预测必将是有偏差的。
Plenary Lecture 1
Chair: Yongmiao Hong, University of Chinese Academy of Science & Xiamen University
Whitney Newey, Massachusetts Institute of Technology
Automatic Debiased Machine Learning via Riesz Regressions

7日下午,麻省理工学院Whitney Newey教授通过两篇论文,和参会者们分享了他在机器学习领域研究的最新进展。
Newey教授首先分享了“Automatic Debiased Machine Learning via Riesz Regressions”这篇论文。在统计学和计量经济学中,我们感兴趣的参数可能依赖于高维回归,机器学习可以被用来估计这些参数。然而,Newey教授指出,基于机器学习的估计量可能会因为正则化或模型选择而产生严重偏差,因此,发掘纠偏机器学习方法是很有必要的。一种减少偏差的方法是使用Neyman正交估计方程。
纠偏机器学习通常需要估计未知的Riesz表示,基于此,Newey教授向我们介绍了论文的第一个创新点:文章提供了Riesz表示的Riesz回归估计量,这些估计量依赖于感兴趣的参数,而不是显式的公式,并且可以使用任何机器学习方法来估计,包括神经网络和随机森林。另一个创新是针对依赖于广义回归的参数(包括高维广义线性模型)的纠偏机器学习方法。Newey教授还给出了使用神经网络的自动纠偏机器学习的实证示例。此外,他们在蒙特卡罗示例中发现,自动纠偏有时比通过逆倾向评分纠偏效果更好。
紧接着,Newey教授向参会者们分享了第二篇论文,“RieszNet and ForestRiesz: Automatic Debiased Machine Learning with Neural Nets and Random Forests”。在这篇论文中,Newey教授和他的合作者们提出了一种多任务神经网络纠偏方法,采用随机梯度下降最小化联合的Riesz表示器和回归损失。他们还提出了一种随机森林方法,它学习了Riesz函数的局部线性表示。通过实验他们发现,对于平均处理效应泛函,与Shi等人(2019)提出的基于神经网络的算法相比,该方法表现良好。
最后,Newey教授和合作者们评估了RieszNet和ForestRiesz在以下两种设置中的表现:二值处理的平均处理效应和连续处理的平均导数。
Plenary Lecture 2
Chair: Yonghong An, Texas A&M University
Arthur Lewbel, Boston College
Estimating Social Network Models with Link Misclassification

8日上午的主题演讲由波士顿学院的Arthur Lewbel教授带来。
在社会网络分析中,邻接矩阵通常用于表示人与人之间的链接关系。Lewbel教授介绍了一种在样本中存在错误链接影响时针对社会网络模型的调整后的二阶段最小二乘(2SLS)估计量。由于调查受访者的记忆误差或数据输入中的疏漏,收集到的邻接矩阵往往会出现错误分类。例如,社交网络中两人本不是朋友却被错误划分为朋友。这种错误分类的链接会使模型中的协变量变为内生变量,并在结构误差和同伴结果之间增加新的相关性来源(除了同时性问题外),从而使文献中使用的常规估计量失效。此研究通过使用错误分类率的估计值来调整内生的同伴结果,并构建利用噪声网络测量特性的新工具变量来解决这些问题。
模拟结果证实,调整后的2SLS估计量可以纠正忽略错误分类并使用常规工具变量的未调整2SLS估计量的偏差。Lewbel教授还介绍了该方法在研究印度村庄中家庭参与小额信贷项目决策中的同伴效应的有效应用。
Plenary Lecture 3
Chair: Farshid Vahid-Araghi, Monash University
Marcelle Chauvet, University of California, Riverside
Forecasting under Nonstationarity: An application to oil prices

8日下午,加州大学河滨分校Marcelle Chauvet教授带来主题报告,通过对比多种模型在预测石油价格和经济变量时的有效性,强调了非线性模型和非平稳特征在经济预测中的重要性。
首先,Chauvet教授用图表直观地展示了宏观经济数据存在的结构性变化,并指出这类非线性和非平稳的特征正是预测经济金融变量的难点与挑战。微观个体在经济繁荣期和衰退期的行为差异带来了经济序列在不同经济周期的非对称特征,而线性模型很难捕捉这种变化,因此难以作为预测经济衰退时点的有效工具。另一方面,如2008经济危机和COVID-19这类经济大事件往往给经济环境带来了持久而强力的冲击,其影响力甚至盖过了其他经济周期的循环特征,因此忽视这些节点会给经济预测带来较大的偏误。
接下来,Chauvet教授以石油价格预测和经济产出预测为例,通过对比线性与非线性模型、没有结构变点和存在结构变点的模型,展示了非线性和非平稳特征在经济动态预测和建模中的重要性。
最后,Chauvet教授提到,利用非线性模型在经济变化期的预测能力,中央银行或政策制定者可以对冲突发性事件带来的影响,也能获得更有效的经济预测结果。
Plenary Lecture 4
Chair: Xiaoyi Han, Xiamen University
Esfandiar Maasoumi, Emory University
Machine Learning Methods: A New Horizon in Econometrics?

9日上午,埃默里大学的Maasoumi教授向与会者们分享了他将机器学应用在计量方向的最新研究。
Maasoumi教授认为计量经济学一定程度上决定了模型中使用的变量和函数,但是由于缺乏所谓的标准随机实验,控制变量和函数的选取不一定正确。这个问题在经济预测研究上尤其突出,会对事实分析产生不可忽略的影响。他指出机器学习(ML)是解决该问题的重要方法,其强大的计算能力在处理大量变量和复杂模型时具有优越性,能够帮助研究者提高预测效果。他同时还分析了机器学习的一些局限性,包括对旧模型规范的依赖,以及在预测和因果分析中的挑战。
接着,Maasoumi教授就ML在计量理论中的应用展开了一系列讨论。他指出在多元回归问题研究中,如果高相关的变量增加相关较高,系数估计值的方差将会以线性速率膨胀,将给传统的计量方法带来挑战。这类问题可以通过添加惩罚项,模型平均等机器学习方法解决。针对不同的机器学习方法,Maasoumi教授详细地讨论它们的优缺点,包括假设性的强弱,以及收敛速度的要求等。
然后,Maasoumi教授主要讨论了ridge(岭)方法在一个同时存在内生变量和外生变量的系统中的应用。对于一个正常的带有内生变量和外生变量的系统,传统的2SLS方法估计是有效且一致的。但是变量存在较强的相关性时候,其方差会变的很高。为了解决这一问题,Maasoumi教授提出基于岭回归的思路,在估计量添加一个’Ridge Variance’项。在此基础上,Maasoumi教授讨论了Aitken 估计量,并详细说明在某些条件下,该估计方法对传统方法的优越性。
在演讲的最后,Maasoumi教授简短地简绍了DML和ML在计量其他领域的应用。比如将SHAPLEY用于合作博弈估计;DML方法在GMM的应用;联合分布中结果的动态分布以及IGM等等。
Plenary Lecture 5
Chair: Yong Bao, Purdue University
Lung-Fei Lee, Shanghai University of Finance and Economics
Maximum Likelihood Estimation of a Spatial Autoregressive Model for Origin-Destination Flow Variables

9日下午,上海财经大学李龙飞教授介绍了他在空间计量经济学方面的最新研究成果。
首先,李龙飞教授指出流量变量的结果数据通常由于预算约束或者地区距离等原因而存在着较多的零值,传统的空间自回归Tobit模型由于只有一个潜在的结果变量而限制了零值和正值的生成机制,同时现有的SARF模型要求能够观测到起点和终点的所有相关特征,从而忽略了可能影响流量的个体效应。
为克服上述局限,李龙飞教授构建了一个SARF hurdle模型。该模型包括了两个阶段的过程,第一阶段决定了个体是否参与即零值的生成;第二阶段决定了潜在的流量水平,其包括了起点和终点的个体效应,同时还包括了3个渠道的空间交互效应,即起点的流出量效应、终点的流入量效应和第三方个体的流量效应。该模型在设定两个阶段变量和参数上的灵活性使得流量变量的零值和正值可以具有不同的生成机制。
其次,李龙飞教授使用极大似然法估计模型中的参数,并基于空间近邻相依(spatial near-epoch dependence)概念分析了估计量的渐近性质,同时发现原估计量存在着来源于固定效应的渐近偏差,他进而提出了纠偏后的极大似然估计量。
最后,李龙飞教授将介绍的方法应用于美国2010年州级移民流数据,发现空间因素尤其是起点的流出量和终点的流入量对移民流有着显著的影响。而相较于SARF Tobit模型,SARF hurdle模型在结果流量的零值上与实际情况更为接近,对数据有更好的拟合结果。
Parallel Sessions
三天会议中,共有69个平行会场、共267位报告人带来论文报告。参会人员覆盖26个国家和地区。
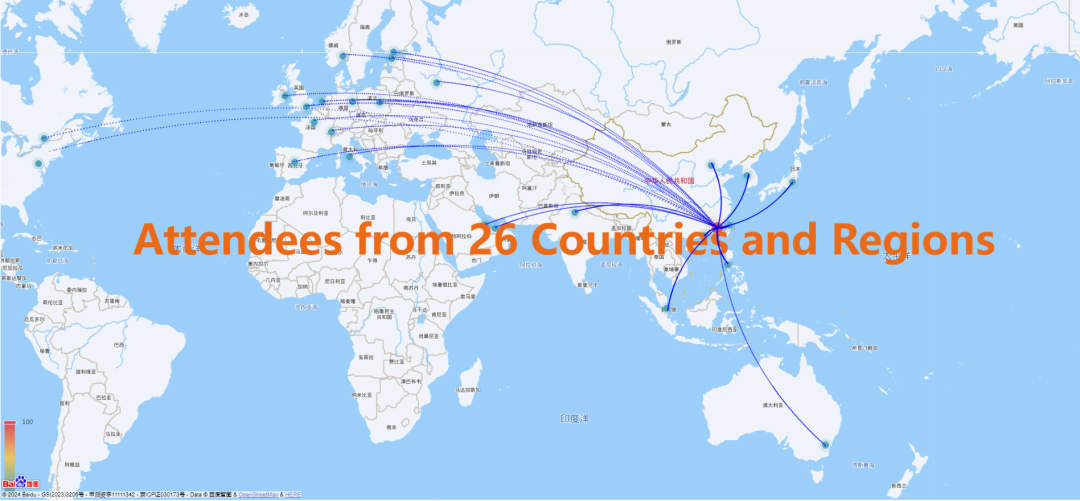
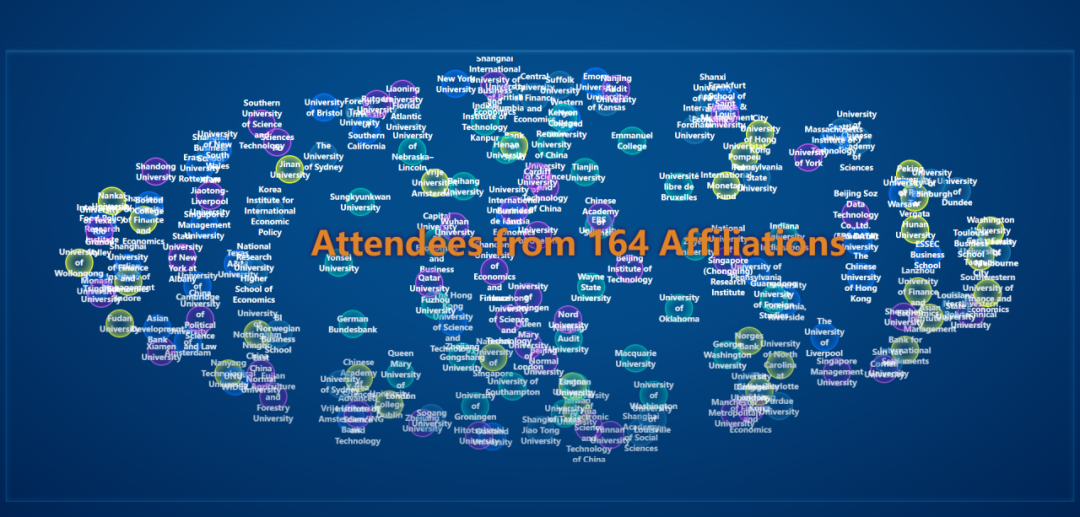
除来自麻省理工学院、纽约大学、宾夕法尼亚州立大学、波士顿大学、奥克兰大学、加州大学河滨分校、西新英格兰大学、德克萨斯农工大学、范德堡大学、不列颠哥伦比亚大学、剑桥大学、伦敦大学学院、ESSEC商学院、图卢兹商学院、罗马第二大学、布里斯托尔大学、鹿特丹伊拉斯姆斯大学、庞贝法布拉大学、穆尔西亚大学、华沙大学、阿姆斯特丹自由大学、新加坡国立大学、南洋理工大学、悉尼大学、莫纳什大学、新南威尔士大学、墨尔本大学、卡塔尔大学、扎耶德大学、秋田国际大学、成均馆大学、香港大学、香港科技大学、台湾清华大学、北京大学、清华大学等境内外高校的学界代表外,还有来自国际粮食研究所、联合国大学世界发展研究院等国际学术研究机构及国际货币基金组织、国际结算银行、亚洲开发银行、德国联邦银行、荷兰商业银行、挪威中央银行、西班牙中央银行等国际金融机构代表人员,总人数近四百人。
本次会议旨在促进中国与世界在计量经济学领域更广泛和密切的交流,共同推进计量经济学科前沿理论与应用的不断优化,在推动经济全球化、维护世界经济稳定、协调可持续发展等方面进行深入探索。
与世界对话,促学术共融,国际应用计量经济学会(IAAE)2024年会至此圆满落幕,期待下次再会!







